|
|

|

|
| e-Pub |
Section: New Results
Facial Analysis
Participants : Antitza Dantcheva, Hung Thanh Nguyen, Philippe Robert, François Brémond.
keywords: automated healthcare, healthcare monitoring, expression recognition, gender estimation, soft biometrics, biometrics, visual attributes
Automated Healthcare: Facial-expression-analysis for Alzheimer's patients in musical mnemotherapy
This work was done in collaboration with Piotr Bilinski (Univ. Oxford, UK), Jean-Claude Broutart (GSF Noisiez, France), Arun Ross (MSU, USA), Cunjian Chen (MSU, USA), Thomas Swearingen (MSU, USA), Ester Gonzalez-Sosa (UAM, Spain) and Julian Fierrez (UAM, Spain), Ruben Vera-Rodriguez (UAM, Spain), Jean-Luc Dugelay (Eurecom, France)
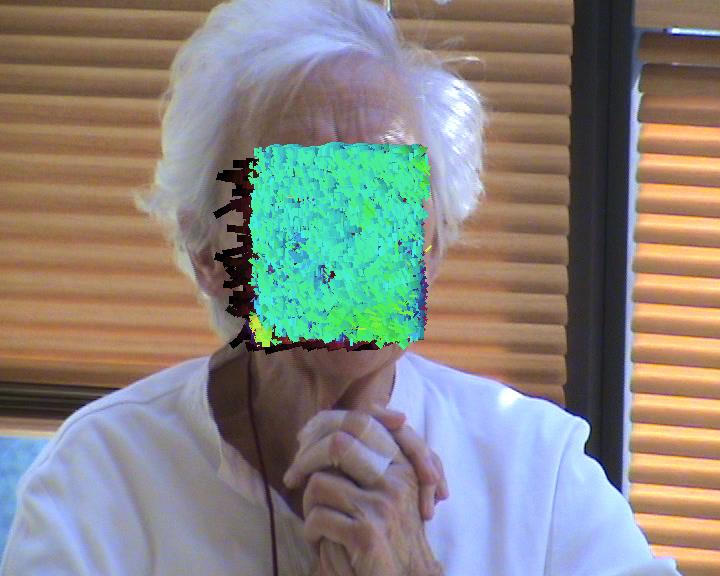
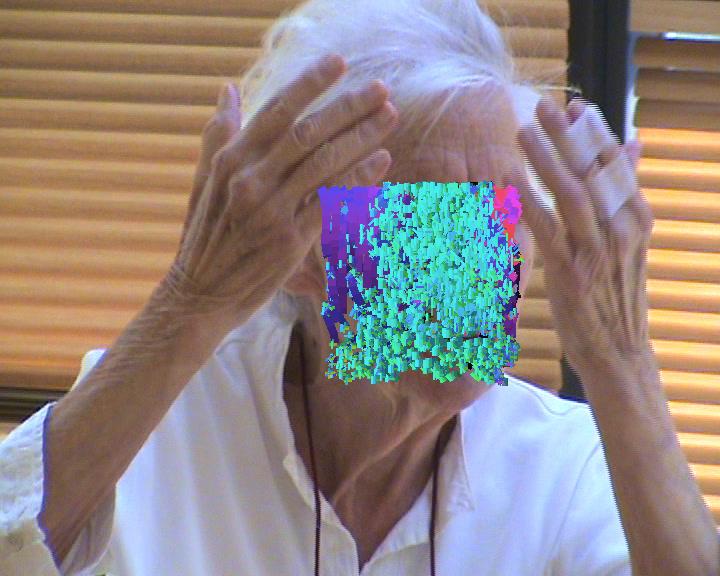
Recognizing expressions in patients with major neurocognitive disorders and specifically Alzheimer's disease (AD) is essential, since such patients have lost a substantial amount of their cognitive capacity, and some even their verbal communication ability (e.g., aphasia). This leaves patients dependent on clinical staff to assess their verbal and non-verbal language, in order to communicate important messages, as of the discomfort associated to potential complications of the AD. Such assessment classically requires the patients' presence in a clinic, and time consuming examination involving medical personnel. Thus, expression monitoring is costly and logistically inconvenient for patients and clinical staff, which hinders among others large-scale monitoring. In this work, we present a novel approach for automated recognition of facial activities and expressions of severely demented patients, where we distinguish between four activity and expression states, namely talking, singing, neutral and smiling. Our approach caters to the challenging setting of current medical recordings of music-therapy sessions, which include continuous pose variations, occlusions, camera-movements, camera-artifacts, as well as changing illumination. An additional important challenge that we tackle has to do with the fact that the (elderly) patients exhibit generally less profound facial activities and expressions, which furthermore occur in combinations (e.g., talking and smiling).
Our proposed approach is based on the extension of the Improved Fisher Vectors (IFV) for videos, representing a video-sequence using both, local, as well as the related spatio-temporal features. We test our algorithm on a dataset of over 229 video sequences, acquired from 10 AD patients. We obtain the best results in personalized facial expression and activity recognition, where we train the proposed algorithm on video sequences related to each patient, individually. The results are promising and they have sparked substantial interest in the medical community. We believe that the proposed approach can play a key part in assessment of different therapy treatments, as well as in remote large-scale healthcare-frameworks.
|
||||||||
|






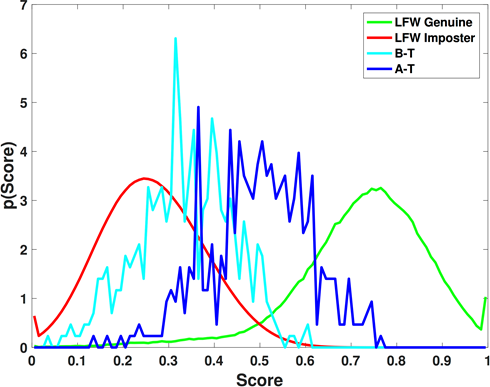
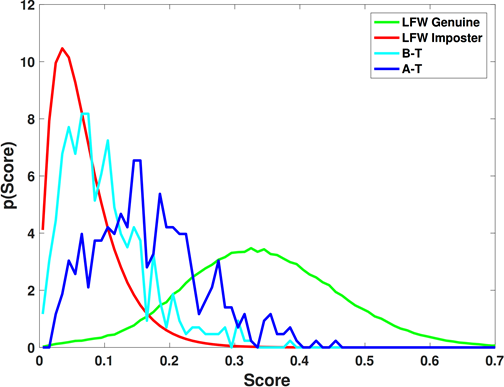
Facial expression and activity recognition [37]
We report the average MCA in Table 3 of the proposed algorithm and 2 further variations thereof. Specifically, we investigate as a first variation (a) the performance without face detection. The rational is that head and hands movement might contain potentially useful information in expression recognition (see Fig. 7). However, we observe that, due to a vast amount of camera-artifacts (i.e., the static background containing a seemingly considerable amount of motion), the analysis of the full-frames reduces the recognition accuracy. Further, we report (b) the performance of the original IFV scheme. Our proposed algorithm significantly outperforms the original IFV-scheme from 50.83% to 53.99% (without face detection), and from 58.4% to 63.37% (with face detection). Additionally, we note that face detection significantly improves the performance of our proposed algorithm, namely from 53.99% to 63.37%.
| IFV, no face detection | 50.83% |
| IFV, face detection | 58.4% |
| Spatio-temporal IFV, no face detection | 53.99% |
| Spatio-temporal IFV, face detection | 63.37% |
Can a smile reveal your gender? [61]
Automated gender estimation has numerous applications including video surveillance, human computer-interaction, anonymous customized advertisement and image retrieval. Most commonly, the underlying algorithms analyze facial appearance for clues of gender.
Deviating from such algorithms in [61] we proposed a novel method for gender estimation, exploiting dynamic features gleaned from smiles and show that (a) facial dynamics incorporate gender clues, and (b) that while for adults appearance features are more accurate than dynamic features, for subjects under 18 years old facial dynamics outperform appearance features. While it is known that sexual dimorphism concerning facial appearance is not pronounced in infants and teenagers, it is interesting to see that facial dynamics provide already related clues.
The obtained results suggest that smile-dynamic include pertinent and complementary to appearance gender information. Such an approach is instrumental in cases of (a) omitted appearance-information (e.g. low resolution due to poor acquisition), (b) gender spoofing (e.g. makeup-based face alteration), as well as can be utilized to (c) improve the performance of appearance-based algorithms, since it provides complementary information.
Vulnerabilities of Facial Recognition Systems
Makeup can be used to alter the facial appearance of a person. Previous studies have established the potential of using makeup to obfuscate the identity of an individual with respect to an automated face matcher. We analyzed [26] the potential of using makeup for spoofing an identity, where an individual attempts to impersonate another person's facial appearance (see Fig. 8). In this regard, we first assembled a set of face images downloaded from the internet where individuals use facial cosmetics to impersonate celebrities. We next determined the impact of this alteration on two different face matchers. Experiments suggest that automated face matchers are vulnerable to makeup-induced spoofing and that the success of spoofing is impacted by the appearance of the impersonator's face and the target face being spoofed (see Fig. 9). Further, an identification experiment was conducted to show that the spoofed faces are successfully matched at better ranks after the application of makeup. To the best of our knowledge, this was the first work that systematically studied the impact of makeup-induced face spoofing on automated face recognition.
|